 ).
).
You'll find links to all of my Irish language projects on the site cadhan.com.
Machine learning plays an important role in most of my work, and I've tried to give a simple introduction to the subject in the activities below. No background in math or computer science is required, outside of a small amount of algebra in Activity 2.
Often in Computer Science we want to place objects into one of two categories; for example:
We can use machine learning to solve problems like these. First, we collect many examples from the two categories (with the correct categories having been marked by humans); these examples make up the training data. Then, we give the training data to the computer so that it can learn from them, and then, hopefully, place new examples into the correct categories (which is to say, generalize from the training data).
A neural network is a mathematical framework that the computer uses to learn from data in this way. There are many other techniques in the field of machine learning, but neural networks are by far the dominant approach in the present day.
Activity 1. Tensorflow Playground.
Spend 5-10 minutes playing with the Tensorflow Playground. We will return to it a bit later, but for now, observe the following:
Activity 2 (optional for those who don't like maths!). What's a neuron exactly and how does it learn?
(Pencil and paper only). Neurons are very simple! We'll focus on the case where the neuron takes just two numbers as input; call these x1 and x2. In this case, the neuron is defined by three numbers (the weights); call these w1,w2, and w3. The neuron combines the weights with the input (x1,x2) as follows:
A = x1 w1 + x2 w2 + w3
And now, the rule:If A≥0, output +1, and if A<0, output -1.
That's it! For example, if the weights are (w1,w2,w3)=(2,2,-3), the neuron will output +1 exactly when:
2x1 + 2x2 - 3 ≥ 0.
In the (x1,x2) plane, these are the points on or above this line:
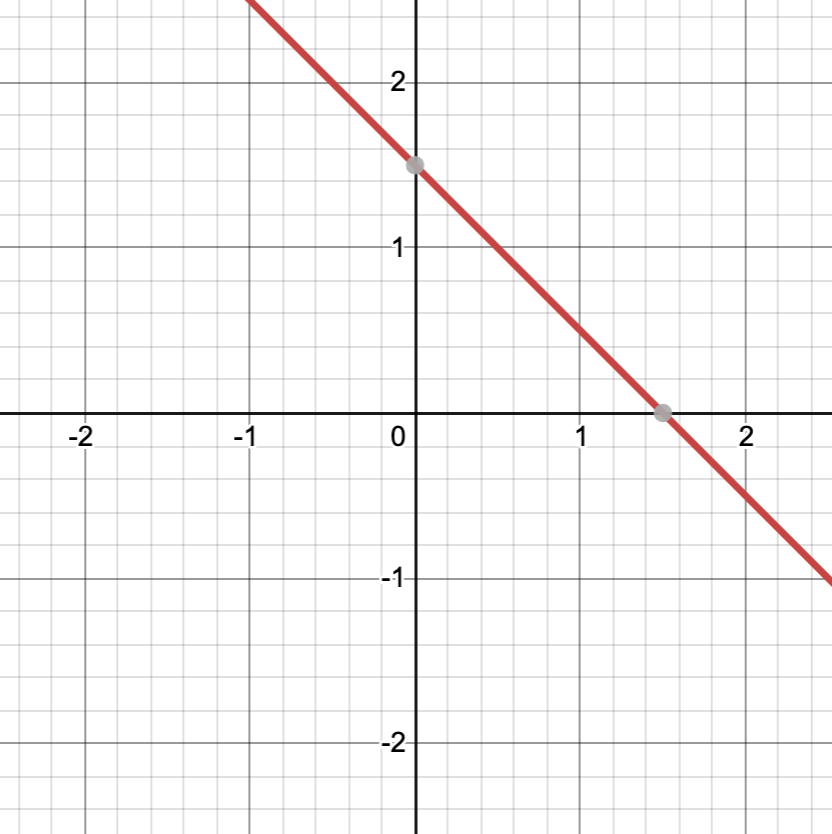
But how does the neuron learn? Where do the weights come from? Let's say we have a problem with two categories (blue and orange) as above, and that we can use two numbers x1 and x2 to describe a given training example. We want to find weights so that the neuron will output +1 for the blue points and -1 for the orange points (if possible). We input a single training example into the neuron, let's say it's a blue (+1) example. If the neuron outputs +1, we're happy and we don't do anything. If it outputs -1, we tweak the weights a little bit to hopefully improve matters. The takeaway here is that the neuron isn't really “learning”; all we're doing is searching for the optimal weights, namely the ones that do the best job separating the blue and orange points. (The technical name for this search process is “stochastic gradient descent”).
Questions:
Activity 3. Back to the playground!
Return now to the Tensorflow Playground, but this time choose the second dataset (on the left hand side, the one that looks like this: ).
If you click the ▶ button now, it will not do such a great job separating the blue and orange points. This happens because a single neuron can only separate the data with a straight line as we saw above in Activity 2. And the dataset here is more complicated — there is no single line so that all the blue points are on one side and the orange on the other (this is also the answer to the third question above in Activity 2, by the way: it is not possible, for the same reason!).
The solution is to use more than one neuron. Click the + button directly above the text “1 neuron”, and then start the training process again. With two neurons, the network can output +1 (or -1) in the region between two straight lines. That's progress, but it's still not ideal.
To get even better results, we need to use more than one layer of neurons, with the output from one layer being fed in as input to the next layer. (This is why this subject is sometimes called deep learning, by the way; deep = more than one layer in the neural network). Click the + button at the top next to “1 HIDDEN LAYER” to add another layer. Then click the + above the first layer so that you have 3 neurons in the first layer and two in the second layer, like this:
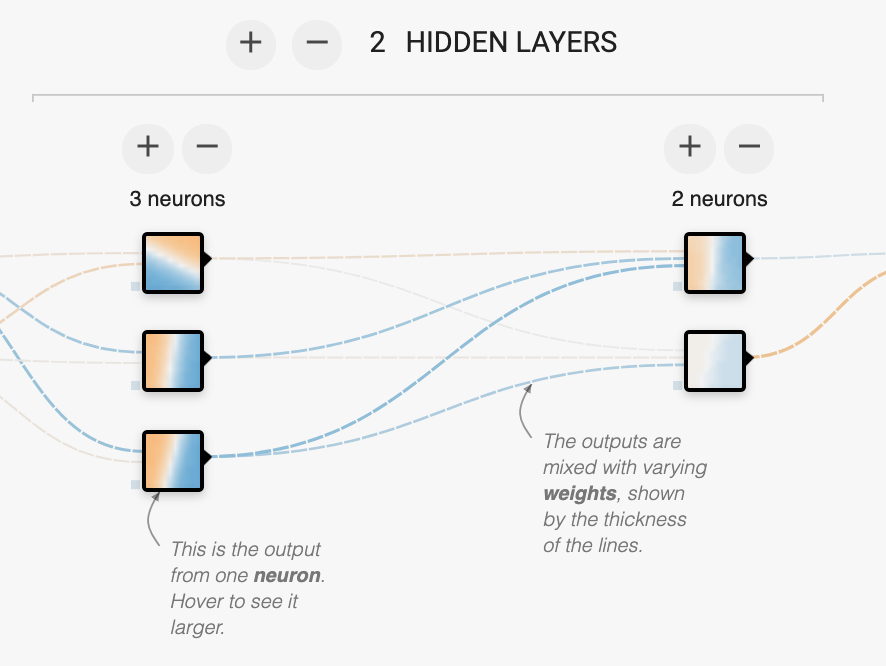
That's 15 weights total (why?). This many weights gives us a lot more freedom to find a more complicated function (one that separates the data effectively, we hope). Now click the ▶ button again. If you're lucky, you will get a picture that resembles the training data; blue in two quadrants and orange in two quadrants. We'd like to achieve a “Test loss” around 0.070 (or smaller), although the exact number will depend on your training/test data — each group will have different data. Click ↺ and then ▶ to restart the learning process; you're likely to get different results each time (this is the “stochastic” part of “stochastic gradient descent”). If you'd like, try using the “Regularization” feature at the top of the screen (e.g. L2 regularization with a rate of 0.003). This helps prevent “overfitting”, or tailoring the weights too closely to the training data so that the network doesn't generalize well to unseen data; you should see a difference in the results, especially when the data is noisy.
Now try the other two datasets that are available. You can get good results on the first one (the two concentric circles) with the same network as above (two layers, five neurons total). But the second dataset (“the spiral”) is much more difficult! Your Challenge: What is the smallest “Test loss” you can achieve on the spiral dataset? First, try this with just two layers. Then see what you can do with additional layers and/or neurons. Regularization will be much more important in this example; experiment with the regularization rate a bit. If the picture or the “Test loss” begin to jump around wildly, it will probably help to decrease the Learning Rate or increase the Regularization Rate.
Automatic translation, or machine translation, is one of the oldest problems in Computer Science, going all the way back to the 1950s and the first generation of computers. In the old days, people tried to use dictionaries and grammatical rules to translate by computer, but it proved very difficult to write comprehensive sets of rules that handled all of the exceptions of natural languages. For the last twenty years or so, approaches based on machine learning have dominated in production systems like Google Translate. Of course Google Translate is far from perfect, but it is much better than the generation of systems that preceded it.
Your challenge in this lab is to translate between two languages without any prior knowledge of either language, based only on a small amount of “training data“, in exactly the way modern machine translation systems do. I will provide 12 sentences in the source language (“Arcturan”), and their translations into the target language (“Centauri”). There are also additional sentences just in Centauri, in case you're able to make use of those in your work. (This exercise is originally due to Prof. Kevin Knight).
First, here are the bilingual sentence pairs (a = Arcturan, b = Centauri):
1a. at-voon bichat dat.
1b. ok-voon ororok sprok.
2a. at-drubel at-voon pippat rrat dat.
2b. ok-drubel ok-voon anok plok sprok.
3a. totat dat arrat vat hilat.
3b. erok sprok izok hihok ghirok.
4a. at-voon krat pippat sat lat.
4b. ok-voon anok drok brok jok.
5a. totat jjat quat cat.
5b. wiwok farok izok stok.
6a. wat dat krat quat cat.
6b. lalok sprok izok jok stok.
7a. wat jjat bichat wat dat vat eneat.
7b. lalok farok ororok lalok sprok izok enemok.
8a. iat lat pippat rrat nnat.
8b. lalok brok anok plok nok.
9a. totat nnat quat oloat at-yurp.
9b. wiwok nok izok kantok ok-yurp.
10a. wat nnat gat mat bat hilat.
10b. lalok mok nok yorok ghirok clok.
11a. wat nnat arrat mat zanzanat.
11b. lalok nok crrrok hihok yorok zanzanok.
12a. wat nnat forat arrat vat gat.
12b. lalok rarok nok izok hihok mok.
And here is the monolingual Centauri text:
ok-drubel anok ghirok farok. wiwok rarok nok zerok ghirok enemok. ok-drubel ziplok stok vok erok enemok kantok ok-yurp zinok jok yorok clok. lalok clok izok vok ok-drubel. ok-voon ororok sprok. ok-drubel ok-voon anok plok sprok. erok sprok izok hihok ghirok. ok-voon anok drok brok jok. wiwok farok izok stok. lalok sprok izok jok stok. lalok brok anok plok nok. lalok farok ororok lalok sprok izok enemok. wiwok nok izok kantok ok-yurp. lalok mok nok yorok ghirok clok. lalok nok crrrok hihok yorok zanzanok. lalok rarok nok izok hihok mok.
The Challenge — translate these sentences from Arcturan to Centauri:
Questions:
This exercise was much simpler than a real bilingual training data. First, the sentences were all very short, and this makes it much easier to align words. Also, there were only a couple of words that were ambiguous (ones that had more than one possible translation). The real world is much more complicated! (Think of all of the Irish words that might translate the single English word “shot” for example). Finally, the number of words in each sentence pair was the same, with the lone exception of (11a/b); this rarely happens in the real world, and one must deal with many examples of words that don't align with anything at all in the other language!